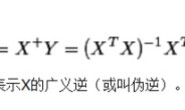回归建模的主要流程:
1、描述性统计:对数据有个概览
2、异常缺失值处理
3、多重共线性检验:kappa(cor(),exact=TRUE)
4、相关性分析:筛选自变量
5、参数计算方法:最小二乘法,岭回归
6、检验:
拟合度检验:R^2
模型显著性检验:F检验的P-value
参数检验:T检验的P-value
残差正太性检验:shapiro.test
残差检验
7、预测:
描述性统计:对数据有个概览
使用R对内置鸢尾花数据集iris(在R提示符下输入iris回车可看到内容)进行回归分析,自行选择因变量和自变量,注意Species这个分类变量的处理方法,完整源码:
iris_data=iris #加载数据
head(iris_data) #查看数据类型
summary(iris_data) #查看数据分布
pairs(iris_data) #查看数据建的关系
#构建哑变量,当is_setosa为1,is_virginica为0时候是setosa,当is_setosa为0,is_viriginca为1时是virginica,
#当两者均为0时,是versicolor
iris_data$is_setosa[which(iris_data$Species=='setosa')]=1
iris_data$is_setosa[which(iris_data$Species!='setosa')]=0
iris_data$is_virginica[which(iris_data$Species=='virginica')]=1
iris_data$is_virginica[which(iris_data$Species!='virginica')]=0
attach(iris_data)
lm_iris_data=lm(Petal.Length~Sepal.Length+Petal.Width+is_setosa+is_virginica)
summary(lm_iris_data)
lm_iris_data=lm(Petal.Length~Sepal.Width+Sepal.Length+Petal.Width+is_setosa+is_virginica-1)
summary(lm_iris_data)
lm_iris_data_res=residuals(lm_iris_data) #残差检验
head(lm_iris_data_res)
shapiro.test(lm_iris_data_res)
plot(lm_iris_data_res)过程:
iris_data=iris #加载数据
head(iris_data) #查看数据类型数据结果:

可以知道iris一共有5个变量,其中4个是数值,1个是文本
summary(iris_data) #查看数据分布
pairs(iris_data) #查看数据建的关系

 从上面可以知道,Spetal.Legth和Petal.Length有相关关系,Petal.Length和Petal.Width有相关关系,可以构建Petal.Length与其他变量的回归关系,Species的种类不同明对其他变量有明显的差异,所以Species为分类变量,需要引入哑变量
从上面可以知道,Spetal.Legth和Petal.Length有相关关系,Petal.Length和Petal.Width有相关关系,可以构建Petal.Length与其他变量的回归关系,Species的种类不同明对其他变量有明显的差异,所以Species为分类变量,需要引入哑变量
iris_data$is_setosa[which(iris_data$Species=='setosa')]=1
iris_data$is_setosa[which(iris_data$Species!='setosa')]=0
iris_data$is_virginica[which(iris_data$Species=='virginica')]=1
iris_data$is_virginica[which(iris_data$Species!='virginica')]=0
attach(iris_data)
lm_iris_data=lm(Petal.Length~Sepal.Width+Sepal.Length+Petal.Width+is_setosa+is_virginica)
summary(lm_iris_data)

截距未通过参数检验,需要将截取去除

从上面可以看到R^2的值高达0.9961,模型的拟合度是非常好的;P-value远小于0.001,模型是非常显著的;各项参数系数都的都是非常显著
残差检验:


P-value远大于0.05,残差符合正太分布,所以回归方程为
Petal.Length=-0.16558Sepal.Width+0.65398Sepal.Length+0.62555Petal.Width-1.39809 is_setosa+0.46806is_virginicais_setosa和 is_virginica的 取值只能是0和1,当is_setosa为1,is_virginica为0时候是setosa类,当is_setosa为0,is_viriginca为1时是virginica类,当两者均为0时,是versicolor类
2 使用R对内置longley数据集进行回归分析,如果以GNP.deflator作为因变量y,问这个数据集是否存在多重共线性问题?应该选择哪些变量参与回归?
longley_data=longley #加载数据
head(longley_data) #查看数据类型
summary(longley_data) #查看数据分布
kappa(cor(longley_data[2:7]),exact=TRUE) #看是否存在多重共线性
cor(longley_data[2:7]) #查看变量间的相关性
lm_longley_data=lm(GNP.deflator~GNP+Unemployed+Armed.Forces,data=longley_data)
summary(lm_longley_data)
lm_longley_data=lm(GNP.deflator~GNP,data=longley_data)
summary(lm_longley_data)
lm_longley_data_res=residuals(lm_longley_data) #残差检验
head(lm_longley_data_res)
shapiro.test(lm_longley_data_res)
plot(lm_longley_data_res))过程:
longley_data=longley #加载数据
head(longley_data) #查看数据类型
summary(longley_data) #查看数据分布
全部为数值型变量
kappa(cor(longley_data[2:7]),exact=TRUE) #看是否存在多重共线性
cor(longley_data[2:7]) #查看变量间的相关性
Kappa的值为14550,远大于1000,存在多重共线性,通过相关系数分析可以知道GNP和Population、Year和Employed存在较强相关性,所以保留GNP建立回归模型
lm_longley_data=lm(GNP.deflator~GNP+Unemployed+Armed.Forces,data=longley_data)
summary(lm_longley_data)
两个变量未通过参数检验,去除
lm_longley_data=lm(GNP.deflator~GNP,data=longley_data)
summary(lm_longley_data)
R^2=0.9832,模型拟合度讲好,模型的P-value远小于0.001,模型显著;
各参数都显著
lm_longley_data_res=residuals(lm_longley_data) #残差检验
head(lm_longley_data_res)
shapiro.test(lm_longley_data_res)
plot(lm_longley_data_res)


正太检验的P-value为0.3345,远大于0.05,符合正太分布,所以回归方程为:
Log(PageViews)=1.30976*Log(uniquevisitors)3、对top 1000 sites(数据集上传在课程资源里)分析进行改进,使到带pageviews的预测模型的检验指标比幻灯片里所显示的更加理想
top.1000.site<-read.csv('C:/Users/ASUS/Desktop/top_1000_sites.tsv',sep='\t',
stringsAsFactors=FALSE) #加载数据
head(top.1000.site) #查看数据格式
summary(top.1000.site) #查看数据分布
attach(top.1000.site)
plot(log(UniqueVisitors),log(PageViews)) # 查看对数散点图分布
top_lm=lm(log(PageViews)~log(UniqueVisitors))
summary(top_lm)
top_lm=lm(log(PageViews)~log(UniqueVisitors)-1)
summary(top_lm)
top_lm=lm(log(PageViews)~log(UniqueVisitors)+HasAdvertising-1)
summary(top_lm)
abline(top_lm)
top_lm_res=residuals(top_lm) #残差检验
head(top_lm_res)
shapiro.test(top_lm_res)
plot(top_lm_res)
par(mfrow=c(2,2))
plot(top_lm)
top.1000.site_1=top.1000.site[-c(45,93,548,956,687,89,953,685,88,950,683,87,947,681,86,944,679,85),]
# 去除异常值
attach(top.1000.site_1)
top_lm_1=lm(log(PageViews)~log(UniqueVisitors)+HasAdvertising-1)
summary(top_lm)
top_lm_1_res=residuals(top_lm_1) #残差检验
head(top_lm_1_res)
shapiro.test(top_lm_1_res)
plot(top_lm_1_res)
par(mfrow=c(2,2))
plot(top_lm_1)过程:
top.1000.site<-read.csv('C:/Users/ASUS/Desktop/top_1000_sites.tsv',sep='\t',
stringsAsFactors=FALSE) #加载数据
head(top.1000.site) #查看数据格式
summary(top.1000.site) #查看数据分布
多为文本格式,不能直接用pairs函数
attach(top.1000.site)
plot(log(UniqueVisitors),log(PageViews)) # 查看对数散点图分布
两者间存在回归关系,可以用于建模,同时预计回归方程可能通过圆点
top_lm=lm(log(PageViews)~log(UniqueVisitors))
summary(top_lm)

检验拟合度的R^2不理想,下面将截距去掉
top_lm=lm(log(PageViews)~log(UniqueVisitors))
summary(top_lm)

各项检验都通过
abline(top_lm)
top_lm_res=residuals(top_lm) #残差检验
head(top_lm_res)
shapiro.test(top_lm_res)
残差检验P-value远小于0.001,残差非正太分布
plot(top_lm_res)
par(mfrow=c(2,2))
plot(top_lm)
将异常点去除
top.1000.site_1=top.1000.site[-c(45,93,548,956,687,89,953,685,88,950,683,87,947,681,86,944,679,85),]
# 去除异常值
attach(top.1000.site_1)
top_lm_1=lm(log(PageViews)~log(UniqueVisitors)+HasAdvertising-1)
summary(top_lm)
top_lm_1_res=residuals(top_lm_1) #残差检验
head(top_lm_1_res)
shapiro.test(top_lm_1_res)

残差检验还通不过,继续将异常点去除
plot(top_lm_1_res)
par(mfrow=c(2,2))
plot(top_lm_1)
循环将异常点去除,直到残差检验通过,这里就不继续下去
Log(PageViews)=1.30976*Log(uniquevisitors)